
Data engineering focuses on building the systems that collect, store, process, and manage massive amounts of data efficiently. It transforms raw data from multiple sources into clean, organized, and usable information that businesses can rely on. From analytics and reporting to machine learning and AI applications, data engineering serves as the foundation of every modern data-driven system.
Becoming a data engineer can feel overwhelming at first because of the number of tools and technologies involved. That’s why following a clear learning path is important. This Data Engineer roadmap provides a structured, step-by-step guide to help you understand what to learn first and how to progress toward advanced concepts and tools. By following this roadmap, you can stay focused, avoid random learning, build practical real-world skills, and prepare confidently for a successful career in data engineering.
Who is a Data Engineer?
A data engineer is a professional who designs, builds, and manages systems that handle large amounts of data. They collect data from different sources, clean and organize it, and store it in databases or data warehouses. Their work ensures data is reliable, secure, and easy to access. Data engineers support data analysts and data scientists by providing high-quality data, helping organizations make informed decisions using accurate and well-structured information.
Key Responsibilities of a Data Engineer
- Build and maintain data pipelines that collect data from different sources, process it correctly, and store it in databases or data warehouses for further use.
- Design, manage, and optimize databases and data warehouses so data remains well-structured, scalable, and easy to access when needed.
- Clean, transform, and validate raw data to ensure accuracy and consistency
- Improve system performance by optimizing data workflows, reducing processing delays, and ensuring pipelines run smoothly without failures.
- Work with cloud platforms and big data tools to handle large-scale data storage and processing across distributed systems.
- Apply data security rules, access controls, and governance practices to protect sensitive data and maintain compliance standards.
Why Data Engineering Is Important in the Digital Age
Data engineering is important in the digital age because organizations generate massive amounts of data every day. Data engineers build systems that collect, process, and organize this data so it can be used effectively. Without proper data engineering, raw data remains scattered and difficult to analyze.
By ensuring data quality, reliability, and accessibility, data engineering helps businesses make faster and smarter decisions. It also supports advanced technologies like analytics, artificial intelligence, and machine learning, making data engineering a critical foundation for modern digital growth.
Recommended Professional Certificates
Full Stack Development Course with AI Engineering
WordPress Bootcamp
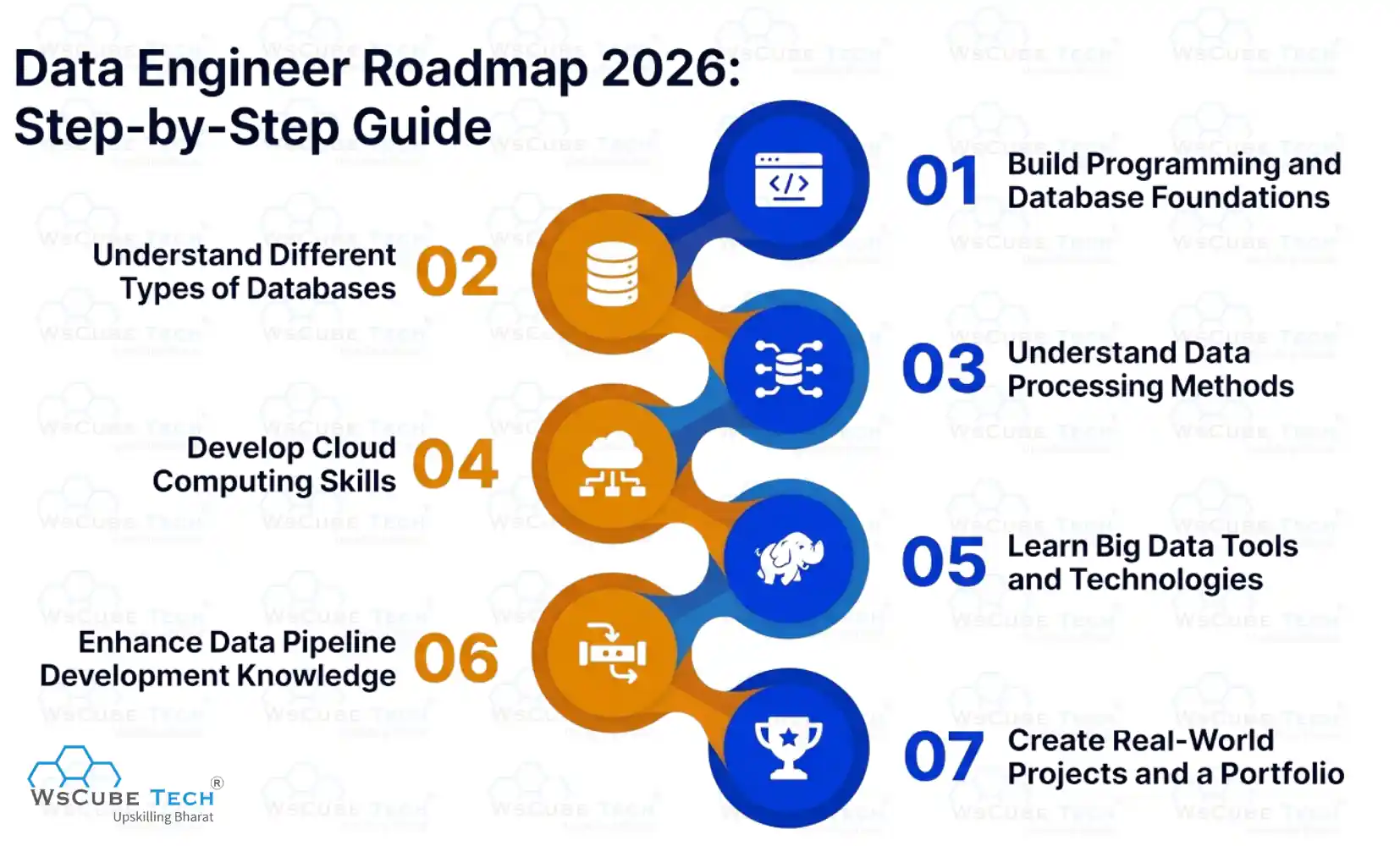
Data Engineer Roadmap 2026: Step-by-Step Guide
This guide presents a clear and practical learning roadmap for anyone who wants to become a data engineer. Following our roadmap for data engineers helps you to learn skills in the correct order, build strong foundations, and move confidently toward real-world, job-ready data engineering roles. It reduces confusion and ensures we focus on the most important concepts at each stage of learning.
Below are the key steps we should follow step by step in our data engineering journey:
- Build Programming and Database Foundations
- Understand Different Types of Databases
- Understand Data Processing Methods
- Develop Cloud Computing Skills
- Learn Big Data Tools and Technologies
- Enhance Data Pipeline Development Knowledge
- Create Real-World Projects and a Portfolio
Next, we will go through each step one by one to clearly explain what we should learn, how to practice effectively, and how to progress confidently in our data engineering learning journey.
Step 1: Build Programming and Database Foundations
This is the first and most important step in the data engineering journey. We start by learning basic programming and database concepts because they are used in almost every data engineering task. Strong foundations help us understand data pipelines, processing logic, and database operations more easily in later steps.
- Python: Learn Python basics such as variables, data types, loops, functions, and working with files. Python is widely used for data processing, automation, and building data pipelines.
- SQL: Learn how to write SQL queries to retrieve, filter, and manage data. SQL helps you work with databases, tables, and real-world data efficiently.
Step 2: Understand Different Types of Databases
In this step, we learn how different databases store and manage data. Understanding database types helps us choose the right database for different use cases and build efficient data systems. Data engineers work with multiple databases based on data volume, structure, and performance needs.
- Relational Databases: Learn databases like MySQL and PostgreSQL that store structured data in tables with fixed schemas and use SQL to query and manage data.
- NoSQL Databases: Understand databases like MongoDB and Cassandra that manage large-scale, unstructured, or semi-structured data using flexible schemas and are suitable for scalable and high-volume data storage.
- Data Warehousing: Data warehousing stores large volumes of historical data from multiple sources in one centralized system, making it easier to analyze data, understand patterns, and support long-term business decisions.
Step 3. Understand Data Processing Methods
Data processing is a core part of data engineering that focuses on turning raw data into useful and meaningful information. Learning these techniques helps us manage large datasets efficiently and select the right processing method based on speed, accuracy, and business requirements.
- Batch Processing: Batch processing collects data over a fixed period and processes it together at scheduled times. It is commonly used when immediate results are not required and large volumes of historical data must be handled efficiently.
- Real-Time Processing: Real-time processing handles data immediately as it is generated. It is useful for live dashboards, system monitoring, alerts, and applications that require instant responses.
- ETL and ELT Concepts: ETL transforms data before loading it into storage, while ELT loads raw data first and transforms it later. Modern cloud systems often prefer ELT for better scalability and flexibility.
Upcoming Masterclass
Attend our live classes led by experienced and desiccated instructors of Wscube Tech.





Step 4. Develop Cloud Computing Skills
As a data engineer, learning cloud computing technologies helps us build scalable, flexible, and cost-efficient data systems. Cloud platforms allow us to store, process, and manage large volumes of data without handling physical infrastructure, making data solutions faster, more reliable, and easier to scale.
Today, most organizations use cloud services for big data and analytics workloads. Understanding platforms such as AWS, Azure, and Google Cloud helps us choose the right tools based on career goals and industry demand. Earning cloud and data engineering certifications is a smart step to strengthen cloud skills and improve job readiness.
Popular certifications to enhance cloud computing knowledge include:
- AWS Cloud Practitioner: Covers core cloud concepts, key AWS services, pricing models, and basic security fundamentals.
- Google Cloud Certified – Professional Data Engineer: Focuses on designing, building, and managing scalable data processing systems on Google Cloud.
- Microsoft Azure Fundamentals (AZ-900): Introduces cloud concepts and essential Azure services used in data solutions.
- AWS Certified Solutions Architect – Associate: Teaches how to design secure, scalable, and reliable cloud architectures for modern data systems.
- IBM Data Engineering Professional Certificate: Provides hands-on learning in data pipelines, databases, and cloud-based data engineering tools.
These certifications help us gain hands-on cloud experience, validate our skills, and prepare confidently for modern data engineering roles.
Step 5: Learn Big Data Tools and Technologies
Big data tools are used to process and manage very large datasets that traditional database systems cannot handle effectively. As data volume and speed continue to grow, learning big data technologies helps us build scalable, reliable, and high-performance data solutions.
- Hadoop Ecosystem: Learn how Hadoop stores and processes large datasets using distributed systems. Understand core components such as HDFS for storage and MapReduce for batch data processing.
- Apache Spark: Master Spark for fast data processing using in-memory computing. It is widely used for batch processing, real-time data processing, and analytics workloads.
- Distributed Computing Concepts: Understand how data is processed across multiple machines. This improves processing speed, fault tolerance, and scalability in large data systems.
- Key Tools to Learn: Focus on Apache Kafka for real-time data streaming, Apache Spark for fast processing, and Hadoop for distributed data storage and processing.
These tools form the foundation of modern big data platforms and are essential for data engineering roles.
Step 6: Enhance Data Pipeline Development Knowledge
Data pipelines are the backbone of data engineering systems. Learning how to build and manage data pipelines helps us move data smoothly from different sources to databases, data warehouses, or analytics tools. This step focuses on understanding how data flows through systems and how to make pipelines reliable and efficient.
We learn how to design pipelines that handle data collection, transformation, and storage. This includes working with scheduling tools, monitoring pipeline performance, and handling failures to ensure data is always available and accurate. Strong pipeline development skills help us manage large-scale data workflows used in real-world applications.
Step 7: Create Real-World Projects and a Portfolio
Working on real projects is one of the most important steps in becoming a data engineer. Projects help us apply what we have learned, understand real data challenges, and gain hands-on experience with tools and technologies used in the industry.
By building a strong portfolio, we can showcase our skills in data pipelines, databases, cloud platforms, and big data tools. Well-documented projects make our resume stronger and help recruiters see our practical abilities, increasing our chances of landing data engineering roles.
Above all, these steps in the data engineer roadmap for beginners help us understand the complete learning path of data engineering. By following them in order, we can build strong foundations, gain practical skills, and confidently progress toward becoming a skilled and job-ready data engineer.
Explore our Roadmap Blogs
Real-World Applications of Data Engineering
Data engineering plays a key role in helping organizations collect, process, and use large amounts of data efficiently. It supports real-time systems, analytics, and decision-making across industries. Below are some important applications that show why data engineering is essential in real-world systems.
1. Business Analytics and Reporting
Data engineering creates data pipelines that gather and prepare information from different sources into a usable form. This organized data helps businesses study performance, track key metrics, recognize patterns, and make reliable, data-driven decisions.
2. Real-Time Data Processing Systems
Data engineering supports real-time systems that process data instantly. These systems are used in applications like live monitoring, alerts, and user activity tracking where immediate data updates are required.
3. Machine Learning and AI Systems
Clean and reliable data pipelines created by data engineers provide high-quality data for machine learning models. This helps improve prediction accuracy and supports AI-based applications in real-world environments.
4. E-commerce and Recommendation Systems
Data engineering helps process user behavior data such as clicks, searches, and purchases. This data is used to build recommendation systems that improve user experience and increase engagement.
5. Financial and Fraud Detection Systems
Data engineering enables processing large volumes of transaction data. It helps detect unusual patterns, identify fraud, and support secure and reliable financial systems in real time.
Career Opportunities After Learning Data Engineering
Following a data engineering roadmap and becoming a data engineer opens many career opportunities by building strong technical skills needed to manage, process, and scale data systems across different industries.
- Data Engineer: Build and maintain data pipelines, databases, and data warehouses to support analytics, reporting, and business applications.
- Big Data Engineer: Work with large-scale data using tools like Hadoop, Spark, and Kafka to process and manage massive datasets.
- Cloud Data Engineer: Design and manage cloud-based data solutions using platforms such as AWS, Azure, or Google Cloud.
- Analytics Engineer: Focus on looking at data modeling and transforming raw data into analytics-ready datasets for business teams.
- ETL / Data Pipeline Engineer: Focus on building and maintaining ETL pipelines that move data from multiple sources into centralized systems while ensuring accuracy, consistency, and timely data availability.
Read More Related Guides
Data Engineer Salary Expectation (India)
- Entry-Level Data Engineer: ₹7 – ₹7.5 LPA
- Mid-Level Data Engineer: ₹11 – ₹12.9 LPA
- Senior Data Engineer: ₹17 – ₹23.8+ LPA
Salaries may vary based on skills, experience, location, and the technologies you work with. Company size, industry domain, cloud expertise, and hands-on project experience can also influence overall compensation and career growth.
Future Scope of Data Engineering
The future of data engineering is very strong as organizations continue to generate massive amounts of data. Companies need skilled data engineers to build reliable systems that manage, process, and deliver data for analytics, automation, and decision-making across industries.
With the growth of cloud computing, big data, and AI, data engineering roles will keep expanding. New tools, real-time data systems, and advanced data platforms will increase demand, making data engineering a stable and high-growth career in the coming years.
Data Engineer Roadmap 2026: Detailed Video Guide
FAQs About Data Engineering Roadmap
A data engineer designs, builds, and maintains systems that collect, process, and store data from multiple sources. You ensure data is clean, well-structured, and reliable so analysts, data scientists, and applications can easily access and use it for better decisions and operations.
You should follow a data engineering roadmap if you want to work with data systems, pipelines, and cloud platforms. It is useful for students, career switchers, and professionals aiming to move into data engineering roles.
Yes, a data engineer roadmap 2026 for freshers is very helpful because it starts from basics. You learn programming, databases, and cloud concepts gradually, making it easier to build confidence and job-ready skills.
Following a data engineer career roadmap usually takes 6 to 18 months, depending on your background. If you already know programming or databases, you progress faster. With consistent practice, projects, and learning core tools, you can become job-ready within this time.
Yes, coding skills are important to become a data engineer. Programming languages like Python and SQL are used to build data pipelines, process data, automate tasks, and work with databases and cloud-based data systems.
Cloud computing is very important in a roadmap for data engineer because most data systems run on cloud platforms. You use cloud services to store, process, and scale large volumes of data easily.
During the data engineer roadmap, you should build projects like data pipelines, ETL workflows, cloud-based databases, and streaming systems. These projects help you apply concepts and show practical skills to recruiters.
Yes, you can follow a roadmap to become a data engineer without experience. By learning step by step and practicing projects, you can build skills gradually and prepare yourself for entry-level data engineering roles.
In a data engineering roadmap, you should learn tools like SQL databases, Apache Spark, Hadoop, Kafka, and cloud services. These tools help you manage large datasets and build scalable data systems.
You can start with cloud-focused certifications like Google Professional Data Engineer or AWS Certified Solutions Architect. These certifications help you understand data pipelines, cloud storage, processing tools, and scalable system design required for real data engineering roles.
Explore Our Free Tech Tutorials
| Python Tutorial | Java Tutorial | JavaScript Tutorial |
| C Tutorial | C++ Tutorial | HTML Tutorial |
| CSS Tutorial | SQL Tutorial | DSA Tutorial |
Practice Coding With Our Free Compilers
| Online Python Compiler | Online HTML Compiler | Online C Compiler |
| Online C++ Compiler | Online JS Compiler | Online Java Compiler |
Free Courses for You





Leave a comment
Your email address will not be published. Required fields are marked *Comments (0)
No comments yet.